
案例介绍
项目名称:巨量星图爬虫项目
项目描述:这个项目旨在使用爬虫技术从巨量星图网站上获取大量的星图数据,并进行存储和分析。
功能要求:
1. 爬取星图数据:通过网络爬虫技术,自动从巨量星图网站上获取星图数据。可以使用Python的爬虫库(如BeautifulSoup或Scrapy)来解析和提取网页中的数据。
2. 存储数据:将爬取到的星图数据存储到数据库或文件中,以便后续的分析和使用。常见的选择包括关系型数据库(如MySQL或PostgreSQL)或NoSQL数据库(如MongoDB)。
3. 数据清洗和处理:对爬取到的数据进行清洗和处理,去除不必要的信息,规范化数据格式,并进行一些基本的数据预处理操作。
4. 数据分析和可视化:利用Python的数据分析库(如Pandas和NumPy)对爬取到的星图数据进行统计分析和可视化展示。可以绘制散点图、柱状图、热力图等图表,从中发现一些有意义的模式和趋势。
5. 高级功能-图像处理:如果需要更详细的分析,可以利用Python的图像处理库(如OpenCV)对星图图像进行处理和特征提取。这样可以获得更多关于星图的信息,例如亮度、颜色、形态等。
6. 高级功能-机器学习:如果有兴趣,可以尝试应用机器学习算法来对星图数据进行分类、聚类或预测。可以使用Python的机器学习库(如Scikit-learn或TensorFlow)来构建模型并进行训练和预测。
7. 异常处理和日志记录:处理可能出现的网络请求异常、数据处理错误等情况,并记录运行过程中的日志信息,以便排查和分析问题。
8. 定时任务:可以使用Python的定时任务库(如APScheduler)设置定时运行爬虫程序,以便定期更新数据。
项目扩展:
1. 多线程或异步处理:在进行大规模爬取时,可以考虑使用多线程或异步处理,提升爬取速度和效率。
2. 分布式爬虫:如果需要爬取更大规模的数据,可以使用分布式爬虫框架(如Scrapy-Redis)来构建分布式爬虫系统,提升爬取能力。
3. 用户界面:如果需要提供给用户交互界面,可以使用Python的GUI库(如Tkinter或PyQt)创建用户友好的界面,方便用户操作和信息展示。
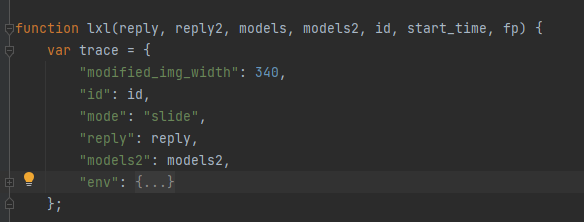
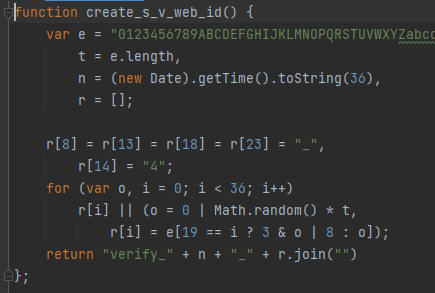
案例图片
相似案例推荐
其他人才的相似案例推荐
-

B2B医药商城
项目描述: 1.未名企鹅B2B医药商城包括:商城,商户端
-

朋贝滩商城
商城版团购APP是一款基于移动互联网的团购商城平台,用户可以
-

科技公司官网
工作内容: 1、参与产品设计:根据业务需求,积极参与产品的
-

商户管理系统
项目: 商户管理系统 开发环境: IDEA + Maven
-

运营管理系统
项目: BOSS运营管理系统 开发环境: Eclipse
-

《先机APP》部分前端页面
深圳农商银行内部的管理的APP,涉及隐私,暂无图片与下载链接
-

橙心优选官网
橙心优选社区电商是滴滴旗下,一家起源成都立足全国的社区电商平
-

MRO工业化采购平台
商城前端采用vue3 elementui框架 ,后端采用ph
-

外贸独立站制作
外贸独立站制作, 制作了多个独立站,全是外贸类型的,都是客
-

进存销采购
进存销采购是基于Java +vuei开发。 功能包含:采购、
-

信用卡产品
乡村振兴产品上线,主要负责中后台商家入驻环境的审核流程及其优
-

saas系统
【主要角色:全面把控者,负责需求审核、评审、任务分配、进度跟
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

