
案例介绍
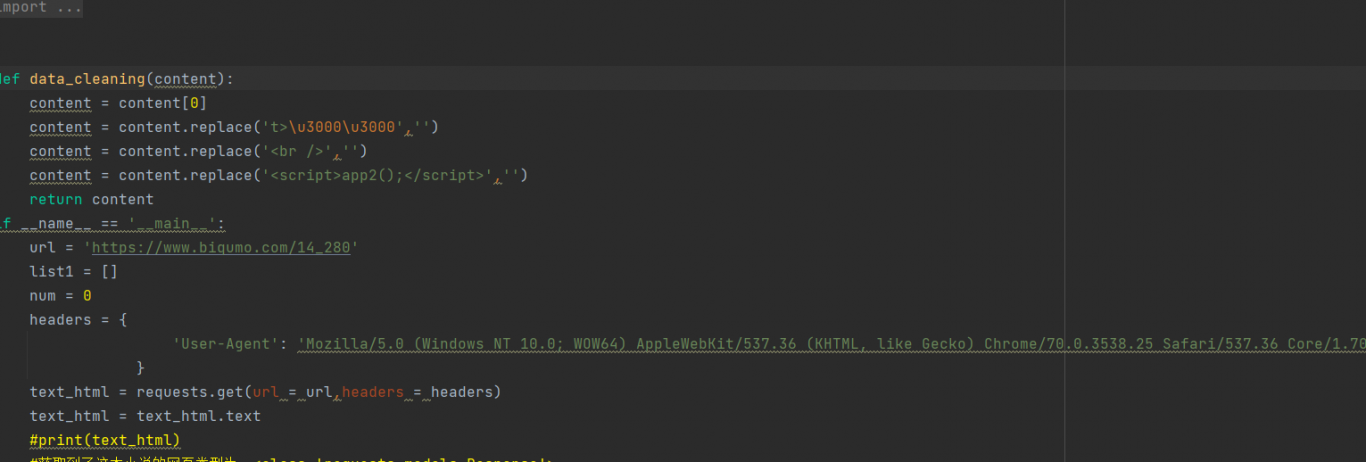
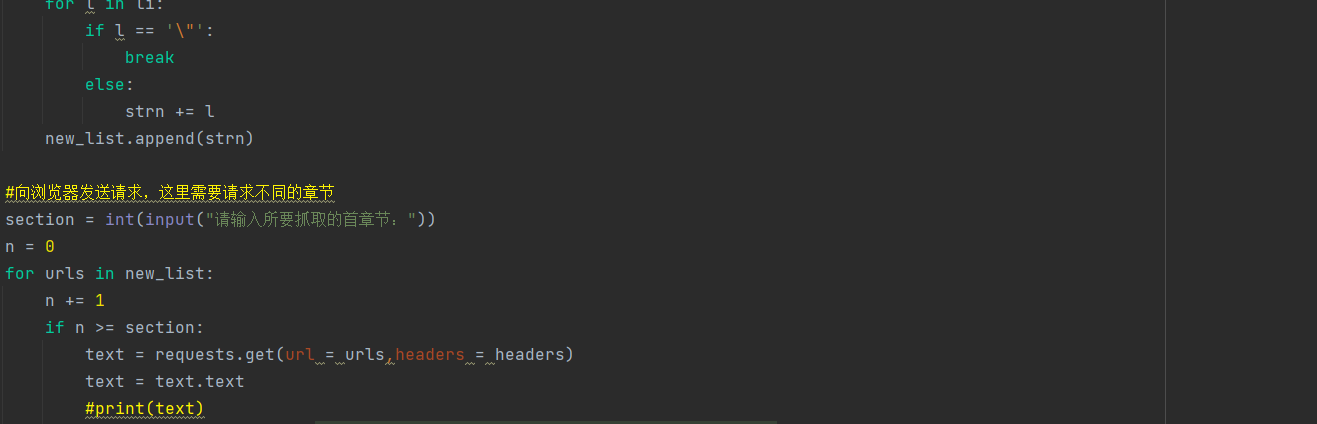
根据难度性,我们先把所有的这个HTML内容响应出来放到一个类集合里面<class 'bs4.BeautifulSoup'>再根据这个集合在检索小说名字和链接所在所在的tag行,形成一个新的集合<class 'bs4.element.ResultSet'>然后再在这个集合里面检索小说名称和小说链接,再形成一个新的类集合<class 'bs4.element.Tag'>在检索的同时就把这些检索出来的东西分别存放在两个字符串里面按照顺序依次遍历出来并把对应小说的内用写在text文件里面
案例图片

相似案例推荐
其他人才的相似案例推荐
-

物联网数据中台
物联网中台目标是基于数据,建设完整的软硬件生态。向下提供公司
-

爱多多·
1.有人脸识别 2.自定义表格和view 3.框架搭建
-

政务服务门户网站
国家政务服务平台作为全国政务服务的总枢纽,重点发挥公共入口、
-

统一预约平台
“统一预约平台”是建设统一的预约服务入口、统一的管理入口,为
-

云调查
云调查为自主研究开发的程序化数据采集平台,包括3个系统,分别
-

BOSS直聘数据抓取
主要是通过在BOSS网站找到大数据相关搜索关键词依次进行抓取
-

新浪舆情通
根据客户方案同步数据 基于您设置的关键词条,可选择只查看某
-

某学校的疫情防控小程序
1.、某学校的疫情防控小程序,主要负责前端开发,根据ui给出
-

某学校的校园卡小程序
某学校的校友卡小程序,主要负责前端开发,这个小程序我负责的是
-

爬虫系统
该项目采用前后端分离的模式开发,后端使用python之dja
-

五位一体安全生产信息化平台
项目分为几大模块 全流程管理,重大危险源,企业安全分区等
-

人员管理系统
该系统为人员管理系统,包含人员库,人员预警等功能 主要负责
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服