
案例介绍
在作品中负责角色有 爬虫
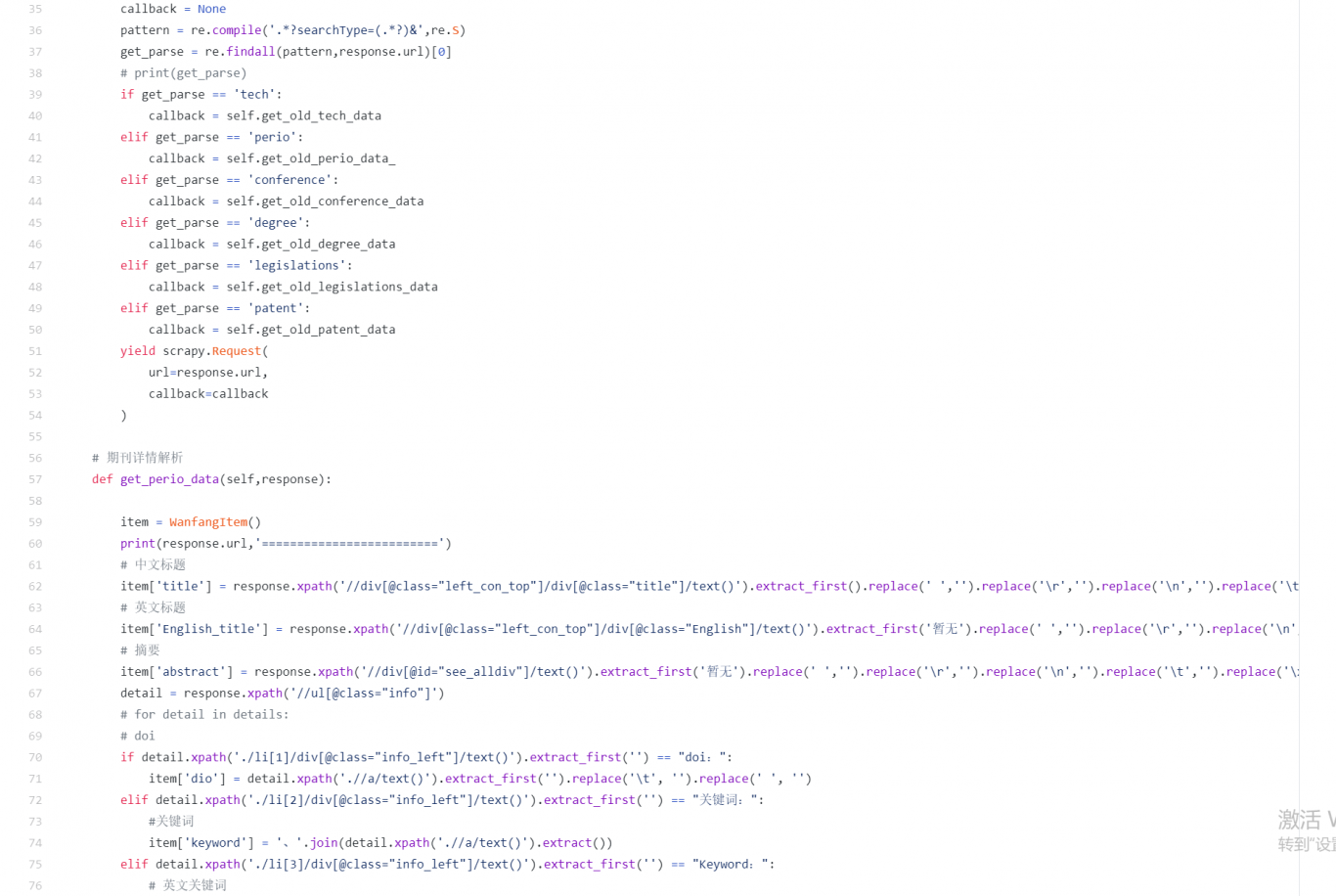
使用 python 的 Scrapy 爬虫框架来实现对页面信息的抓取
根据万方的反爬机制,提出针对性的意见和应急性的处理
它是根据每页最大数量返回信息条数和共返回页数来限制用户获取信息量
由于此网页分旧,新两版 在旧网页没有对返回数据作出限制
用正则取出旧版详情 id 与新版详情 url 拼接
为了实现对商品信息的自动化爬取,利用 Scrapy 框架中的 CrawlSpider 模块对 url 进行过
滤
使用 MySQL 数据库进行信息存储
案例图片
相似案例推荐
其他人才的相似案例推荐
-

暂不上传
暂时无暂时无暂时无暂时无暂时无暂时无暂时无暂时无暂时无暂时无
-

图像处理算法代码截图
有三年算法开发经验,主要从事推荐算法、图像处理、NLP算法开
-

行李箱的检测并进行规格判别
本项目进行行李的检测,判断是拉杆箱还是软包,是否含有托盘等,
-

目标的检测跟踪项目
本项目基于是基于视频的人脸检测并跟踪人脸,同时根据人脸评分机
-

全自动样品处理系统
主要功能:由ATM机进行血液样本交接,前处理进行扫码,配平,
-

营业厅运营App
Android 原生App,App有项目团队共同负责完成,项
-

智能安全帽
项目使用物联网/空间定位/移动通信等技术打造了融合 危险报警
-

个人网站
个人网站,涵盖很多个人爱好内容,博客、自动化、AI、监控..
-

微博任何数据采集
微博什么数据都能做,什么数据都能做,单机数据量 2kw+/一
-

物联网
输电管理平台是一个属于定制化管理平台,它结合现场管理人员的实
-

识酒猫
识酒猫是一家专业的酒水供应品牌,在北京银泰中心和大望路蓝堡国
-

《Taxi: City Run》
《Taxi: City Run》【游戏玩法】 左右轻划
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服